使用 Gemma 3 270M 來做 fine-tuning 有幾個非常實際的原因,就是本地或資源有限的情況:
- 輕量且高效
- 支援 instruction-tuning
- 適合本地 / 邊緣設備
- 省時省錢又快速
- 支援量化與 LoRA 微調
# 1️⃣ 安裝套件
!pip install transformers peft datasets accelerate
# 2️⃣ 導入模組
import os
import torch
from transformers import (
AutoTokenizer, AutoModelForCausalLM,
TrainingArguments, Trainer, DataCollatorForLanguageModeling,
pipeline
)
from datasets import load_dataset
from peft import LoraConfig, get_peft_model, PeftModel
# 禁用 tokenizer parallelism 避免 deadlock
os.environ["TOKENIZERS_PARALLELISM"] = "false"
# 3️⃣ 設定裝置
device = "mps" if torch.backends.mps.is_available() else "cpu"
print("使用裝置:", device)
# 4️⃣ 載入 base model 與 tokenizer
model_id = "google/gemma-3-270m-it"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map={"": device},
dtype=torch.float32
)
# 5️⃣ 載入資料集 (Alpaca 範例)
dataset = load_dataset("yahma/alpaca-cleaned")
# 6️⃣ 合併 instruction/input/output 成 text 欄位
def format_example(example):
if example.get("input"):
return {"text": f"指令: {example['instruction']}\n輸入: {example['input']}\n回覆: {example['output']}"}
else:
return {"text": f"指令: {example['instruction']}\n回覆: {example['output']}"}
dataset = dataset.map(format_example)
# 7️⃣ Tokenize dataset (truncation + padding)
def tokenize_function(example):
return tokenizer(
example["text"],
truncation=True,
padding="max_length",
max_length=512
)
tokenized_dataset = dataset.map(tokenize_function, batched=True)
# 7️⃣b️⃣ 刪掉原始欄位,只保留 input_ids/attention_mask
tokenized_dataset = tokenized_dataset.remove_columns(
[col for col in tokenized_dataset["train"].column_names if col not in ["input_ids", "attention_mask"]]
)
# 8️⃣ 設定 LoRA
lora_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)
# 9️⃣ DataCollator
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)
# 🔟 TrainingArguments
training_args = TrainingArguments(
output_dir="./gemma3-270m-lora-mps",
per_device_train_batch_size=2,
gradient_accumulation_steps=8,
num_train_epochs=1,
learning_rate=2e-4,
logging_steps=10,
save_steps=100,
optim="adamw_torch",
fp16=False,
bf16=False,
remove_unused_columns=False
)
# 1️⃣1️⃣ Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"].shuffle(seed=42).select(range(200)),
tokenizer=tokenizer,
data_collator=data_collator
)
# 1️⃣2️⃣ 訓練
trainer.train()
# 1️⃣3️⃣ 儲存 LoRA checkpoint
model.save_pretrained("./gemma3-270m-lora-mps/checkpoint")
# 1️⃣4️⃣ 重新載入 LoRA 模型進行推理
base_model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map={"": device},
dtype=torch.float32
)
model = PeftModel.from_pretrained(base_model, "./gemma3-270m-lora-mps/checkpoint")
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 1️⃣5️⃣ Pipeline 生成測試
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
device_map={"": device}
)
prompt = "請用繁體中文寫一個有趣的工程師迷因:"
result = pipe(prompt, max_new_tokens=100)
print(result[0]["generated_text"])
prompt = "請用繁體中文寫一個gemma 用lora fine tune:"
result = pipe(prompt, max_new_tokens=100)
print(result[0]["generated_text"])
回答
請用繁體中文寫一個gemma 用lora fine tune:
gemma is a beautiful and gentle female character, known for her quiet and introspective nature. She is often depicted as a kind and compassionate figure, with a gentle smile and a soft, flowing hairstyle. Gemma is a supportive and caring companion, who always listens to her needs and offers her a comforting presence. She is a beloved and cherished member of the community, and her presence is a source of joy and comfort. Gemma is a beautiful and nurturing character, who is always ready to help others
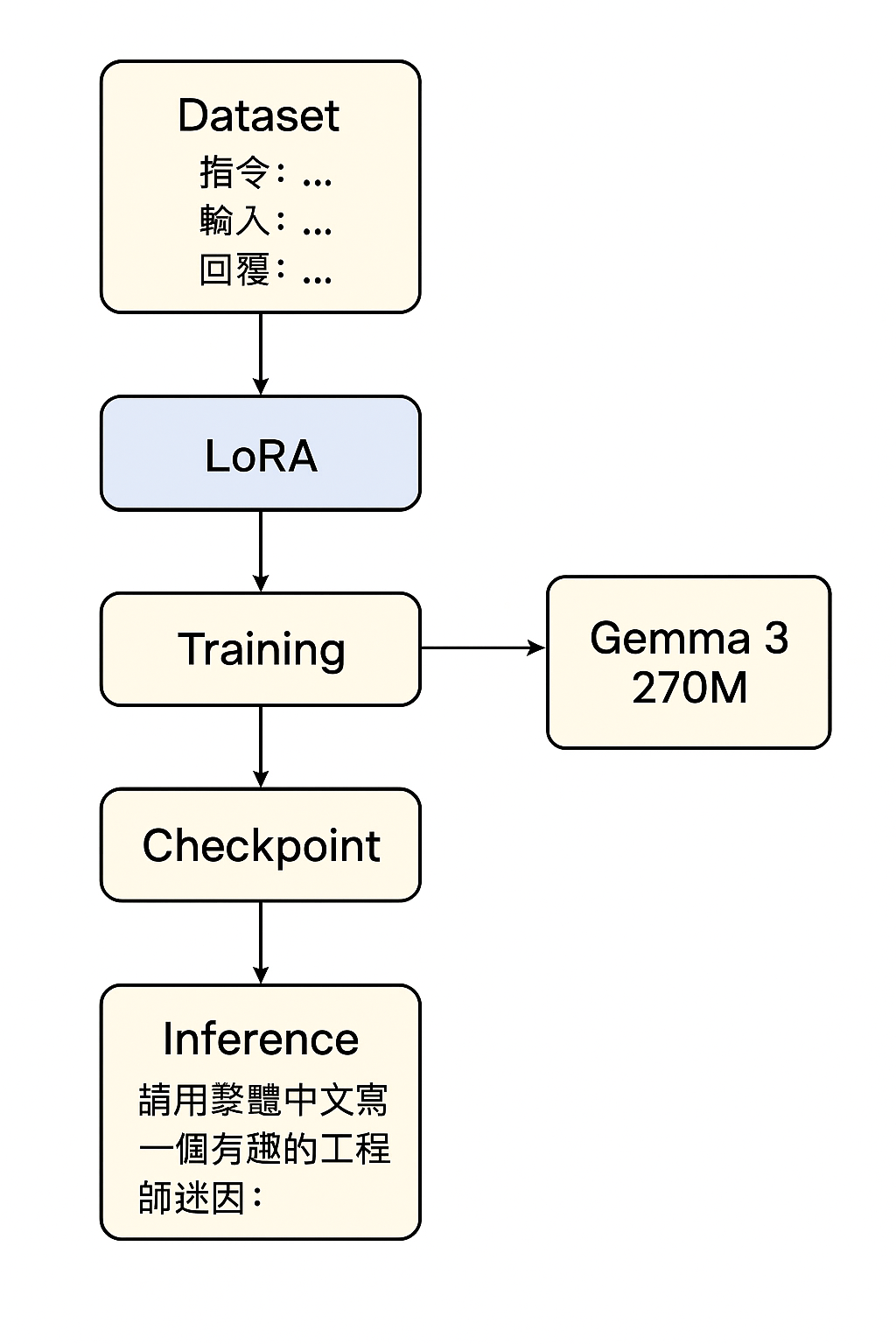
Gemma 3 270M 讓 fine-tuning 變得超簡單:訓練快、硬體需求低,隨手就能做出自己的專屬模型。


 iThome鐵人賽
iThome鐵人賽